It’s been a few weeks since my last discussion1 of Excel 4.0 macro shenanigans and the space continues to change. LastLine published a great report2 which summarized the progression of weaponized macros from February through May. The good folks at InQuest have continued3 identifying4 malicious5 macro documents6. @DissectMalware‘s excellent XLMMacroDeobfuscator7 has massively expanded its range of macro emulation, and FortyNorth Security released EXCELntDonut8, a tool for converting Donut9 shellcode into multi-architecture Excel 4.0 macros.
Over the past few weeks I’ve also started seeing some of the files generated by my tool Macrome10 begin to trigger detections on VirusTotal11. This is exactly the sort of thing I want to see – besides the fact that it implies that AV is getting better signal on this attack vector, it also provides an opportunity to improve my tool and take better guesses about what direction attackers will pivot in the future. I’m a big believer in a @Mattifestation‘s approach to detection engineering12 and detection from AV helps move the iterative development of tooling further along.
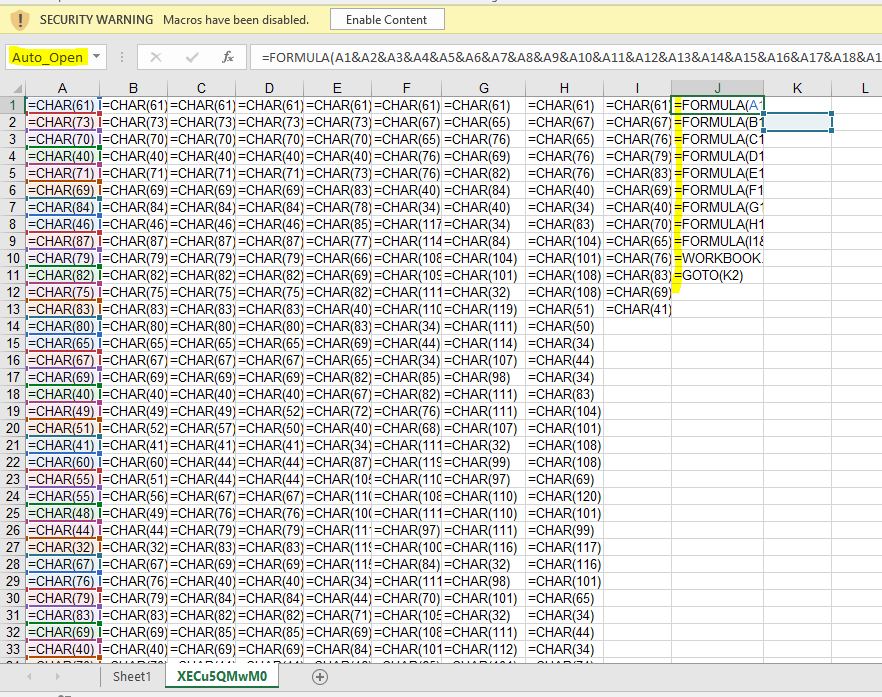
After realizing that some of my samples were being detected, I took several documents that had been generated during testing and submitted each of them to VirusTotal – only the larger documents appeared to be matching virus signatures. I did a quick binary search of the document sizes between what was detected on VirusTotal and what wasn’t and discovered that if a document had greater than 100 CHAR invocations, then it was considered malicious.

While my generated document had obfuscated the usage of the CHAR function, clearly there was a signature that could detect these alternate CHAR invocations. For reference, here is @DissectMalware’s macro_sheet_obfuscated_char rule13 that the generated document attempted to avoid:
rule macro_sheet_obfuscated_char
{
meta:
description = "Finding hidden/very-hidden macros with many CHAR functions"
Author = "DissectMalware"
Sample = "0e9ec7a974b87f4c16c842e648dd212f80349eecb4e636087770bc1748206c3b (Zloader)"
strings:
$ole_marker = {D0 CF 11 E0 A1 B1 1A E1}
$macro_sheet_h1 = {85 00 ?? ?? ?? ?? ?? ?? 01 01}
$macro_sheet_h2 = {85 00 ?? ?? ?? ?? ?? ?? 02 01}
$char_func = {06 ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? 1E 3D 00 41 6F 00}
condition:
$ole_marker at 0 and 1 of ($macro_sheet_h*) and #char_func > 10
}My previous blog post discussed how to break the longer signature for $char_func, but it didn’t address what to do if the signature for the CHAR function were more reliable. In this case the signature was likely only the the three bytes of a PtgFunc14 invocation with the CHAR Ftab value15 (41 6F 00) but repeatedly occurring enough times to avoid false positives. This is likely the reason for the “high” minimum count requirement of 101+ instances versus the 11+ in the macro_sheet_obfuscated_char rule.

One “quick” hack to bypass this signature is to abuse the fact that PtgFuncVar16 can be used instead of PtgFunc to invoke the CHAR function (42 01 6F 00). PtgFuncVar is largely identical to PtgFunc except for the fact that PtgFuncVar must also be provided with the number of arguments being passed into the called function. While PtgFunc is only used to call functions with a fixed number of arguments, there is nothing that stops us from invoking PtgFuncVar and providing the correct argument count. PtgFunc(CHAR) is identical to PtgFuncVar(1,CHAR).
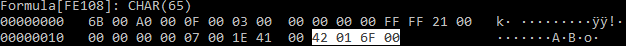
This is a nice signature evasion trick, but it ultimately is vulnerable to the same method of detection, just with a slightly different byte signature. Fundamentally, many tricks that macro sheets rely on in order to deobfuscate themselves will rely on invoking a handful of functions repeatedly. Large macro payloads can require invoking some form of CHAR and FORMULA hundreds of times – what will adversaries do once there are better signatures put into place for detecting suspiciously repeated usages of these functions?
Re-Enter the Subroutine
In normal programming, when we constantly call the same code over and over again, we write a function. Even in VBA macros, the idea of subroutines exist to allow for simple code-reuse. While the Excel 4.0 Macro Functions Reference18 mentions the idea of Excel 4.0 macro subroutines several times – it never actually details how these can be created.
In practice, Excel 4.0 macro subroutines are really just a sequence of RUN and RETURN functions. A subroutine is invoked by calling the RUN function with an argument referencing the start cell of the sub-macro. Execution then starts at that cell and continues down the column until a RETURN function is invoked. The argument passed to RETURN is what the return value of the function will be. For example, if we wanted to create a subroutine that would eventually return the string “Hello World”, it would look something like this:
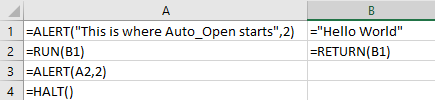
Excel actually even aliases the RUN command by letting users specify a cell reference or cell name and invoke it directly by appending () to the invocation as seen below:
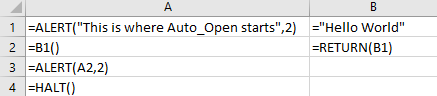

It’s not a very common way to see macros used right now, but malware authors are clearly already aware of this19 as can be seen from a sample shared by @JohnLaTwc and analyzed by @DissectMalware:

While using subroutines in this way might be slightly helpful for slowing analysis of a document, it’s really only dipping its toes into the potential of “proper” subroutine usage in a maldoc. For example, what if instead of having the byte sequence 41 6F 00 every time we invoked CHAR, we moved the CHAR expression into a subroutine and just invoked the subroutine repeatedly? The predictable function invocation would only appear once, and it would be much harder to claim that EVERY usage of CHAR is malicious. Even Windows Defender’s aggressive blocking of =CHAR(#) invocations requires other conditions beyond matching three bytes. Here’s an example of what replacing the CHAR expression with a subroutine looks like:
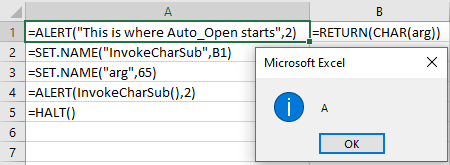
So this is slightly different from our previous examples, but the main difference is that we are invoking SET.NAME in order to specify two values:
- We are defining the value of InvokeCharSub to be equivalent to a reference to cell B1. Later we invoke it using InvokeCharSub(), though we could also use RUN(InvokeCharSub).
- We are setting the value of the name “arg” to 65. This is essentially how we pass arguments to our subroutine. While there does appear to be an ARGUMENT function that allows explicitly defining names to store arguments, I haven’t been able to make this work any differently than just manually setting names or cell values. While porting EXCELntDonut macros into Macrome21 I also realized that you can simply write arg=65 in an Excel cell, and it will automatically be interpreted as SET.NAME(“arg”,65)
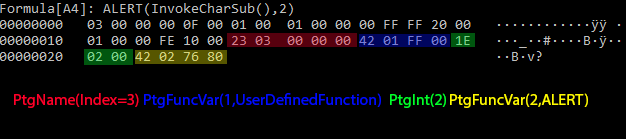
Under the covers when we call InvokeCharSub(), we are having Excel call a user defined function through the PtgFuncVar Parse Thing object. User defined functions are a PtgFuncVar edge case – one of the arguments provided to the PtgFuncVar must be a PtgName22. PtgName objects reference a Lbl23 entry stored within the Excel Workbook’s Globals Substream24. In this case, we are looking for the 3rd Lbl entry in the substream – it’s also worth noting that the index here starts at 1, rather than 0. We’ll come back to some “fun” that malware authors can have with these labels later.
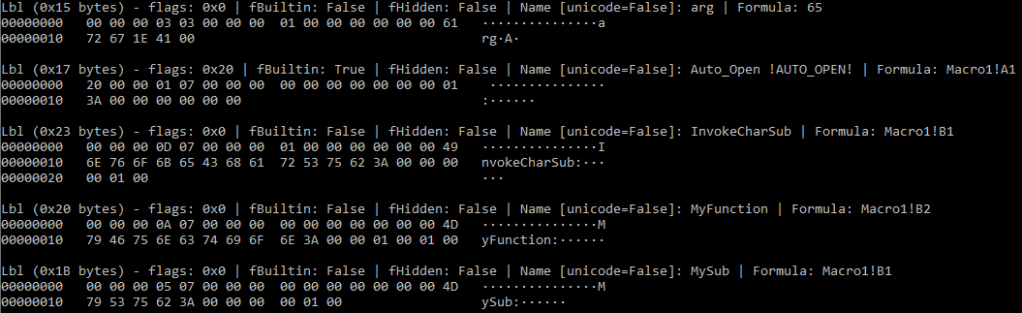
So we have a mechanism to replace our CHAR function invocations with SET.NAME invocation followed by a call to a user defined function. This turns one very simple cell into two cells, but there’s a workaround for that as well. A final possible optimization to reduce the size of our document is to combine our variable assignment with the invocation of our subroutine by abusing the IF function to execute two expressions in a single cell – for example:
=IF(SET.NAME("var",65),invokeChar(),)The invocation of SET.NAME here saves us from having to use two cells to invoke our subroutine and lets us use a single cell which cuts down on our FORMULA record count by about half. This is the approach used by the CharSubroutine method in Macrome10.
Going back to @Mattifestation‘s detection engineering approach – let’s think about how we could detect this sort of approach and then analyze it. From a detection standpoint, a massive number of invocations of SET.NAME and PtgFuncVar objects with a user defined function would likely stand out. For example, if we look at the above IF statement at the byte level we get something like:

We can create a signature for this by keying on the presence of a PtgFuncVar invocation of SET.NAME (42 02 58 00) with some arbitrary locality to a PtgFuncVar invoking a user defined function (42 ?? FF 00 – the Ftab value is FF 00, but we need a wildcard since we can’t necessarily guess the argument count). Our signature doesn’t need to care if SET.NAME comes before or after the user defined function, we just want to check for a large number of these instances. A Yara25 signature for this could look like:
rule msxls_set_name_and_invoke_udf
{
meta:
description = "Finding XLS2003 documents with a suspicious number of SET.NAME and User Defined Function invocations"
Author = "Michael Weber (@BouncyHat)"
strings:
$ole_marker = {D0 CF 11 E0 A1 B1 1A E1}
$setname_invokeudf = {42 02 58 00 [0-100] 42 ?? FF 00}
$invokeudf_setname = {42 ?? FF 00 [0-100] 42 02 58 00}
condition:
$ole_marker at 0 and (#setname_invokeudf > 100 or #invokeudf_setname > 100)
}Note that the wildcard range [0-100] probably makes this computationally expensive to run on a large dataset, but the upper bound of 100 wildcard bytes could be lowered as needed.
This signature could still be avoided (as is true for most signatures) with a little additional effort on the part of the attacker. As demoed in Outflank’s research26, we can use Excel’s WHILE functionality to iterate over a column of seemingly harmless numbers and use them to build strings of binary data or additional macro statements to populate with the FORMULA function.

But let’s assume that there is a foolproof signature to identify our document and that our document has made its way into the hands of an analyst armed with a tool like XLMMacroDeobfuscator6 or olevba27. Are there any weird behaviors that can be abused to trick analysts attempting to examine our document? Thanks to Excel’s “flexibility” with Lbl records, the answer is yes.
(Ab)Using Names in Excel 4.0 Macros
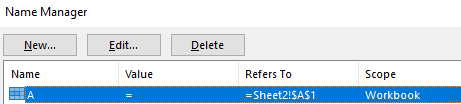
The usage of Lbl record lookups when resolving names is another opportunity for malware authors to frustrate analysis. In my previous blog post1 I discussed how Excel’s flexible handling of the Auto_Open Lbl record made signature creation extremely challenging. It seems like similar issues would apply to “variable” and subroutine name invocation as well. For example – what would you expect the output of the following macro sheet to be?
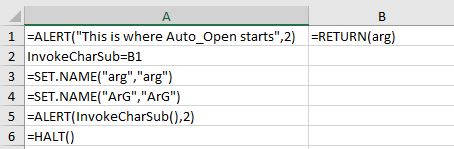
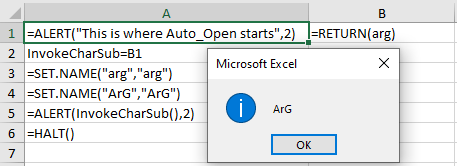
This looks like a nice trick, but it doesn’t appear to do much to frustrate analysis – at a glance. Just HOW flexible is Excel’s interchangeability with upper case and lower case letters?

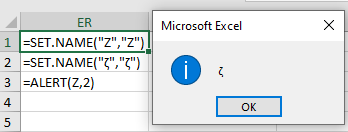
It’s pretty flexible. There are a surprising number of multi-case characters to confuse Excel, just take a glance at the library of valid lower case Unicode characters28. Unfortunately, for defenders, the PtgStr record29 used by Excel to invoke SET.NAME will happily allow attackers to set arbitrary Unicode content for arguments, so this is a challenging situation to avoid. The issues don’t stop at casing confusion either – Excel also respects Unicode Equivalence30. This behavior, which is part of the Unicode specification31, is a consistent32 source of pain33 in the security world34.
One example of how Unicode Equivalence can frustrate analysis is Decomposed Unicode. Decomposed Unicode values are alternate representations of Unicode characters that use a series of characters instead of a single Unicode character. For example – consider the Unicode character ḁ35. This can be represented as 2 bytes in UTF-16 (Excel’s Unicode interpretation) as 1E 01. Alternatively, we can represent it as the letter a and the ◌̥ combining diacritical mark36 – or 00 61 03 25. (Note: These diacritical marks are the same bit of fun that can be used to create Zalgo monstrosities37)
There also exist Unicode characters, like the Combining Graphene Joiner38 (03 4F) which are essentially no-op characters for most Unicode strings. The Wikipedia article for the character explicitly describes it as “default ignorable” in the first sentence:
“The combining grapheme joiner (CGJ), U+034F ͏ COMBINING GRAPHEME JOINER (HTML
https://en.wikipedia.org/wiki/Combining_Grapheme_Joiner͏) is a Unicode character that has no visible glyph and is “default ignorable” by applications.”
Finally, there are a sizable number of Unicode whitespace characters39 which can change the byte contents of a string without changing its appearance. The “most interesting” of these whitespace characters are the zero-width Unicode characters. A zero-width character makes no visible change to the label. Some of these characters are ignored by Excel when comparing strings (U+200C, U+200D, U+2060, and U+FFEF), but others (U+180E and U+200B) are not. These characters can be used to pad variable names, or create decoy names that look the same but are not actually assigned when invoking SET.NAME.
There’s nothing fundamentally bad about following the Unicode specification, but combining support for Unicode equivalence with some of Excel’s other flexibility can lead to very counter-intuitive equivalencies. For example, 1E 01 (ḁ) is considered the same as 20 60 00 41 03 25 03 4F 00 (a decomposed Ḁ with some ignored Unicode characters added to the string). Replacing some of those bytes with a 18 0E or 20 0B would break the equivalency as well, which allows us to create strings that look identical, but are not treated as such by Excel. In practice this lets us create, using Macrome’s10 AntiAnalysisCharSubroutine method, the following content :
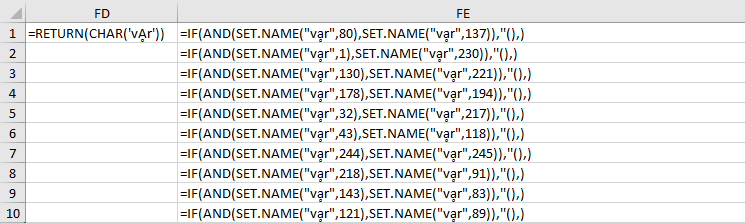
Although the vḁr strings appear to be identical, they are in fact quite different on disk. This means that any analysis of the cell to figure out what will actually happen will require running Excel or manually reproducing Excel’s EXACT handling of Unicode characters. Reproducing the behavior is going to require handling a lot of edge cases. If you want a sense of what analysts could be up against, here’s what the above example looks like in binary:
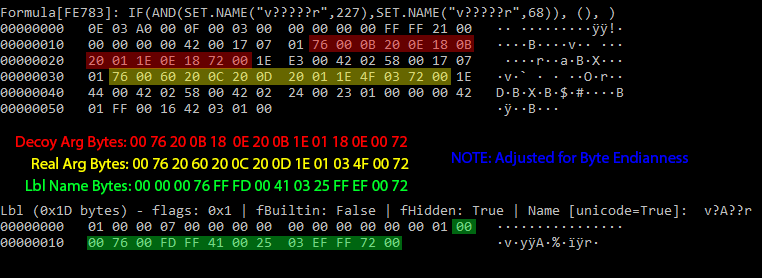
In the above example the “Real” argument bytes are considered a match for the Lbl name bytes, but the “Decoy” argument bytes are not. The fact that Lbl record strings can be so wildly different from the PtgStr arguments passed to SET.NAME makes it challenging to follow Excel’s data flow without actually running Excel. Even then, Excel isn’t consistent with handling Unicode values – see what happens when null bytes are injected into the Auto_Open label after the u character:
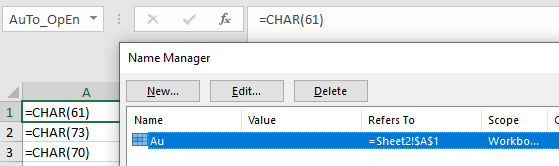
Given the already low detection rate for Excel 4.0 macros in the wild, we may never see attackers need to rely on this level of trickery. If AV does start getting better signal with their signatures though, I will not be surprised to see various forms of Unicode abuse begin to crop up.
Updates to Macrome
In the process of digging deeper into Excel documents, I’ve often come across a need to examine the byte content of specific records as a hex dump. While I don’t mind crawling through a wall of hex text, I’ve managed to save some time by modifying my tool Macrome to dump the hex content of Lbl and Formula records. All of the hex examples from this post were generated using this dump functionality. I’ve also implemented code for generating proof-of-concept documents using some of the subroutine and Unicode shenanigans that I discussed in this post. If you want to try generating some malicious documents to see how your tooling will handle these kinds of documents I’d suggest heading over to https://github.com/michaelweber/Macrome and grabbing the latest release.
As always, if folks have any suggestions for features or improvements, please let me know here in the comments or open an issue on the Github project page.
References
- https://malware.pizza/2020/05/12/evading-av-with-excel-macros-and-biff8-xls/
- https://www.lastline.com/labsblog/evolution-of-excel-4-0-macro-weaponization/
- https://inquest.net/flash-alerts/IQ-FA004%3AMultiple_Actors_Abusing_New_Macro_Methods
- https://twitter.com/InQuest/status/1268568312499376130
- https://twitter.com/DissectMalware/status/1268491222299086854
- https://github.com/DissectMalware/XLMMacroDeobfuscator
- https://twitter.com/Anti_Expl0it/status/1269895583633829888
- https://github.com/FortyNorthSecurity/EXCELntDonut/
- https://github.com/TheWover/donut
- https://github.com/michaelweber/Macrome
- https://www.virustotal.com/gui/file/b159b25b80b1830acf40813c06a48f3e72666720b7efcd406ea5031c7f214c31/detection
- https://twitter.com/mattifestation/status/1263416936517468167
- https://pastebin.com/V8SGgdZL
- https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-xls/87ce512d-273a-4da0-a9f8-26cf1d93508d
- https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-xls/00b5dd7d-51ca-4938-b7b7-483fe0e5933b
- https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-xls/5d105171-6b73-4f40-a7cd-6bf2aae15e83
- https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-xls/8e3c6978-6c9f-4915-a826-07613204b244
- https://exceloffthegrid.com/using-excel-4-macro-functions/
- https://twitter.com/DissectMalware/status/1269535826813366273
- https://www.virustotal.com/gui/file/a53be0bd2a838ffe172181f3953a2bc8a1b7c447fb56d885391921a7c3eac1f9/details
- https://github.com/michaelweber/Macrome/releases/tag/0.2.0
- https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-xls/5f05c166-dfe3-4bbf-85aa-31c09c0258c0
- https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-xls/d148e898-4504-4841-a793-ee85f3ea9eef
- https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-xls/ca4c1748-8729-4a93-abb9-4602b3a01fb1
- https://virustotal.github.io/yara/
- https://outflank.nl/blog/2018/10/06/old-school-evil-excel-4-0-macros-xlm/
- https://github.com/decalage2/oletools/wiki/olevba
- https://www.compart.com/en/unicode/category/Ll
- https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-xls/87c2a057-705c-4473-a168-6d5fac4a9eba
- https://en.wikipedia.org/wiki/Unicode_equivalence
- https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf
- https://www.dionach.com/en-us/blog/fun-with-sql-injection-using-unicode-smuggling/
- https://hackernoon.com/%CA%BC-%C5%9B%E2%84%87%E2%84%92%E2%84%87%E2%84%82%CA%88-how-unicode-homoglyphs-will-break-your-custom-sql-injection-sanitizing-functions-1224377f7b51
- https://book.hacktricks.xyz/pentesting-web/unicode-normalization-vulnerability
- https://www.compart.com/en/unicode/U+1E01
- https://www.compart.com/en/unicode/U+0325
- https://zalgo.it/en/
- https://en.wikipedia.org/wiki/Combining_Grapheme_Joiner
- https://en.wikipedia.org/wiki/Whitespace_character